Line Buffer Convolution Implementation
Created by: Keb-L
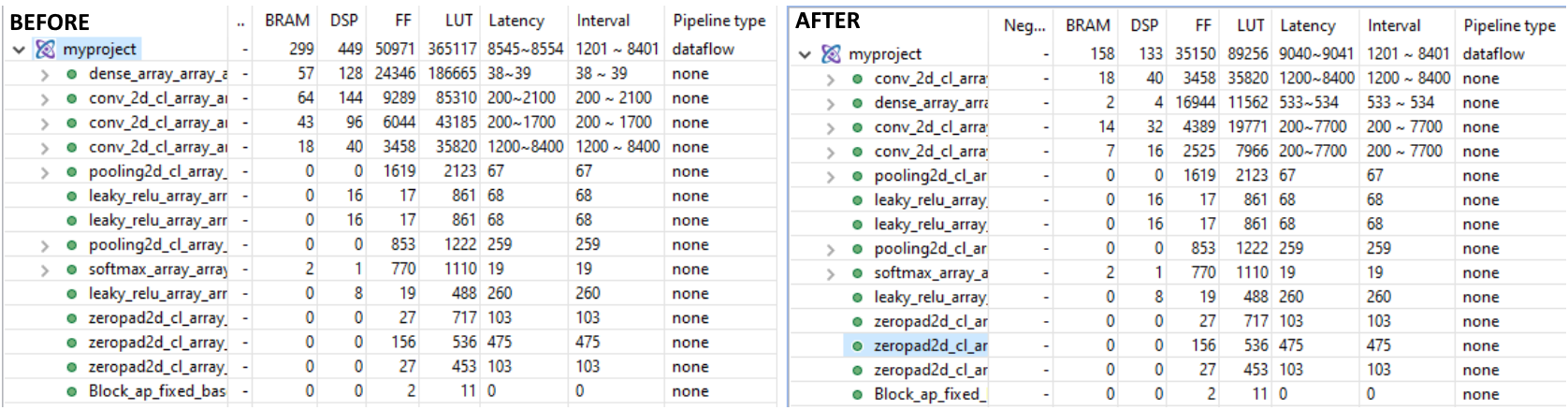
This PR introduces an alternative stream-based implementation for Convolutional (and Pooling) layers that reduces resource utilization compared to the current implementation. Additionally, this PR introduces some new YAML configuration parameters (ConvImplementation, BramFactor, TargetCycles).
The new convolution implementation, called "Line Buffer", uses shift registers to keep track of the last <kernel height - 1> rows of input pixels and maintains a shifting snapshot of the convolution kernel. This implementation supports non-square kernels and strides greater than the width of the kernel. See the following animation for a demonstration of the Line Buffer implementation.
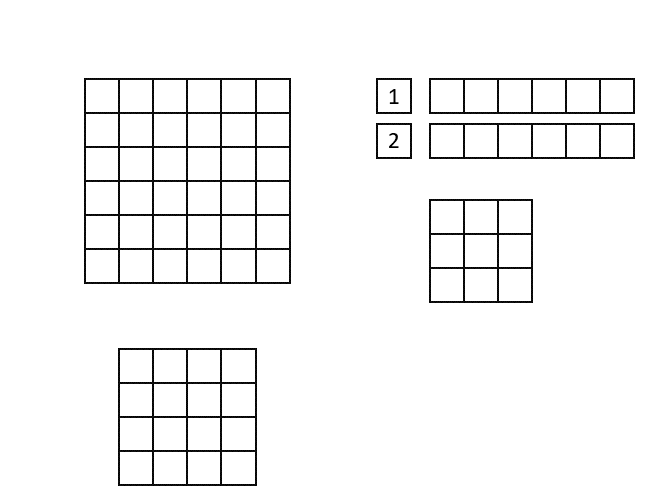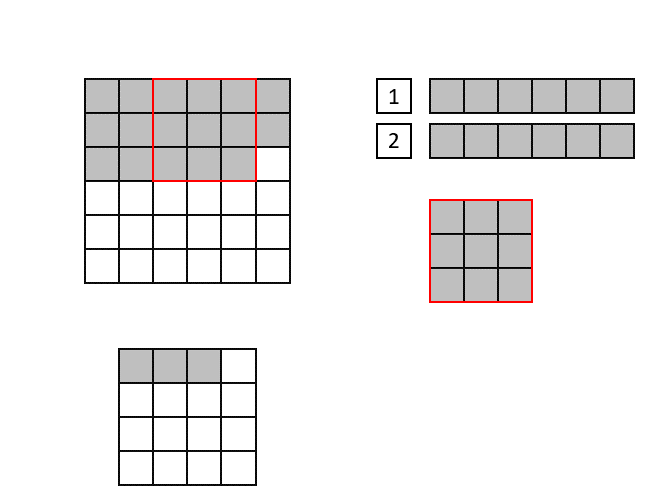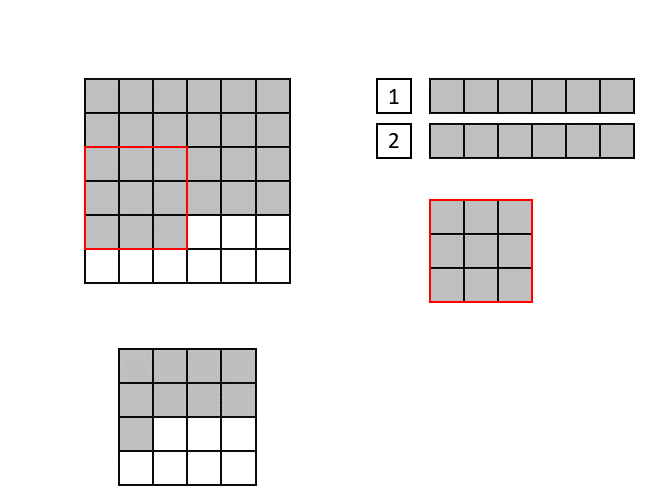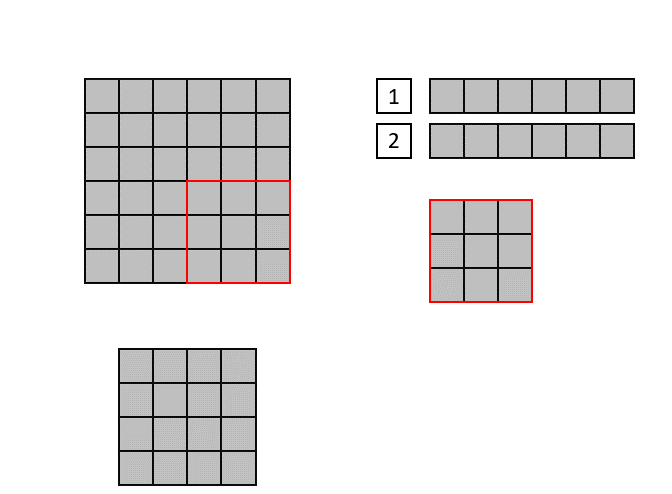 (Input image is at the top-left, output image on the bottom left. The top right shows the internal state of the shift registers and convolutional kernel. The red square indicates the current pixels contained within the convolutional kernel)
(Input image is at the top-left, output image on the bottom left. The top right shows the internal state of the shift registers and convolutional kernel. The red square indicates the current pixels contained within the convolutional kernel)
A YAML configuration has been added (see YAML Configuration additions) to mix-and-match between the two convolution implementations. The line buffer implementation has been set to be the default. Top-level functions have been changed to be a switch between the two convolution implementations.
Updated layers:
-
Conv1D,Conv2D -
DepthwiseConv1D,DepthwiseConv2D -
Pooling1D,Pooling2D
YAML Configuration additions:
-
ConvImplementation- Flag to switch between Line Buffer (added) and Encoded (current) implementations. Functions similarly to the softmax implementation parameter. Values:
linebuffer(default),encoded
- Flag to switch between Line Buffer (added) and Encoded (current) implementations. Functions similarly to the softmax implementation parameter. Values:
-
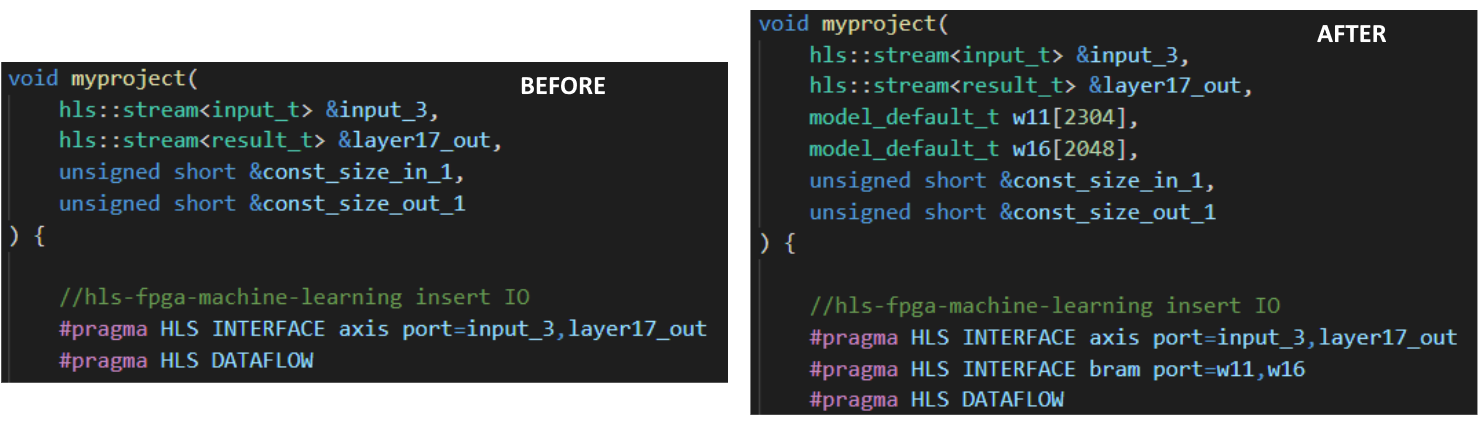
BramFactor- Threshold value to import weights as BRAM ports. Importing weights as BRAM ports reduces synthesis time. Defaults to infinity.

- Threshold value to import weights as BRAM ports. Importing weights as BRAM ports reduces synthesis time. Defaults to infinity.
-
TargetCycles- Balances throughput of
Conv1D,Conv2D,Denselayers by tuning the Reuse Factor to achieve specified latency in clock cycles. Reduces resource utilization by slowing down fast layer (experimental). Defaults to None (unused).
- Balances throughput of
Current limitations:
- Target Cycles still requires further tuning to be more broadly applicable. It works in most cases, but is not guaranteed to achieve the specified latency in all cases. Further studies are needed to tune the RF computation.
- Pooling using kernels of height 1 do not work with line buffer implementation. This will be fixed in a future PR.